Basic Overview
This guide will provide a basic overview of the dataclocklib library, including how to create charts and utilise the utility functions. The data and Jupyter Notebook used in this guide is available at the library GitHub repository:
Here we install dataclock library and download the data ready for visualisation. The data has already been cleaned and preprocessed in a way that can be used by the dataclocklib.charts.dataclock function.
%pip install -U dataclocklib
import pandas as pd
data = pd.read_parquet(
"https://raw.githubusercontent.com/andyrids/dataclocklib/main/tests/data/traffic_data.parquet.gzip"
)
Data clocks visually summarise temporal data in two dimensions, revealing seasonal or cyclical patterns and trends over time. A data clock is a circular chart that divides a larger unit of time into rings and subdivides it by a smaller unit of time into wedges, creating a set of temporal bins.
We import the dataclock function like below:
from dataclocklib.charts import dataclock
Everything is documented, including public modules and docstrings, which can be printed using the help function. Full API documentation is also available on the documentation site.
help(dataclock)
Help on function dataclock in module dataclocklib.charts:
dataclock(data: 'DataFrame', date_column: 'str', agg_column: 'Optional[str]' = None, agg: 'Aggregation' = 'count', mode: 'Mode' = 'DAY_HOUR', cmap_name: 'str' = 'RdYlGn_r', cmap_reverse: 'bool' = False, spine_color: 'str' = 'darkslategrey', grid_color: 'str' = 'darkslategrey', default_text: 'bool' = True, *, chart_title: 'Optional[str]' = None, chart_subtitle: 'Optional[str]' = None, chart_period: 'Optional[str]' = None, chart_source: 'Optional[str]' = None, **fig_kw) -> 'tuple[DataFrame, Figure, Axes]'
Create a data clock chart from a pandas DataFrame.
Data clocks visually summarise temporal data in two dimensions,
revealing seasonal or cyclical patterns and trends over time.
A data clock is a circular chart that divides a larger unit of
time into rings and subdivides it by a smaller unit of time into
wedges, creating a set of temporal bins.
TIP: Palettes - https://python-graph-gallery.com/color-palette-finder/
Args:
data (DataFrame): DataFrame containing data to visualise.
date_column (str): Name of DataFrame datetime64 column.
agg (str): Aggregation function; 'count', 'mean', 'median',
'mode' & 'sum'.
agg_column (str, optional): DataFrame Column to aggregate.
mode (Mode, optional): A mode key representing the
temporal bins used in the chart; 'YEAR_MONTH',
'YEAR_WEEK', 'WEEK_DAY', 'DOW_HOUR' & 'DAY_HOUR'.
cmap_name: (str, optional): Name of a matplotlib/PyPalettes colormap,
to symbolise the temporal bins; 'RdYlGn_r', 'CMRmap_r',
'inferno_r', 'Alkalay2', 'viridis', 'a_palette' etc.
cmap_reverse (bool): Reverse cmap colors flag.
spine_color (str): Name of color to style the polar axis spines.
default_text (bool, optional): Flag to generating default chart
annotations for the chart_title ('Data Clock Chart') and
chart_subtitle ('[agg] by [period] (rings) & [period] (wedges)').
chart_title (str, optional): Chart title.
chart_subtitle (str, optional): Chart subtitle.
chart_period (str, optional): Chart reporting period.
chart_source (str, optional): Chart data source.
fig_kw (dict): Chart figure kwargs passed to pyplot.subplots.
Raises:
AggregationColumnError: Expected aggregation column value.
AggregationFunctionError: Unexpected aggregation function value.
EmptyDataFrameError: Unexpected empty DataFrame.
MissingDatetimeError: Unexpected data[date_column] dtype.
ModeError: Unexpected mode value is passed.
Returns:
A tuple containing a DataFrame with the aggregate values used to
create the chart, the matplotlib chart Figure and Axes objects.
The dataclock chart function expects:
PandasDataFrame (data).Name of the datetime formatted column (date_column).
Name of the column to aggregate (agg_column).
Only required if aggregation function is not ‘count’.
Name of the aggregation function (agg).
Functions; ‘count’, ‘mean’, ‘median’, ‘mode’ & ‘sum’.
Default is ‘count’.
Chart mode, representing how to divide the temporal elements of the data (mode).
Modes; ‘YEAR_MONTH’, ‘YEAR_WEEK’, ‘WEEK_DAY’, ‘DOW_HOUR’ & ‘DAY_HOUR’.
The first part of the mode refers to rings and the second refers to the wedges.
Default mode is ‘DAY_HOUR’.
NOTE: Be mindful of the temporal range in your data when choosing a mode. If you have 5+ years of data and choose to represent each day of the year as a ring, with the hours of the day as wedges (‘DAY_HOUR’) then the chart will likely not generate or be too crowded. In this instance, ‘DOW_HOUR’ mode would be better as it can visualise that amount of data, by grouping it by days Monday - Sunday. You could also split your data down and apply the function on the grouped data.
Below we create a simple chart from the data, but we prevent any default column generation, with the default_text=False. We are visualising the data by day of the week (Monday - Sunday) as rings and by hour of day as wedges.
chart_data, fig, ax = dataclock(
data=data,
date_column="Date_Time",
mode="DOW_HOUR",
spine_color="darkslategrey",
grid_color="black",
default_text=False
)
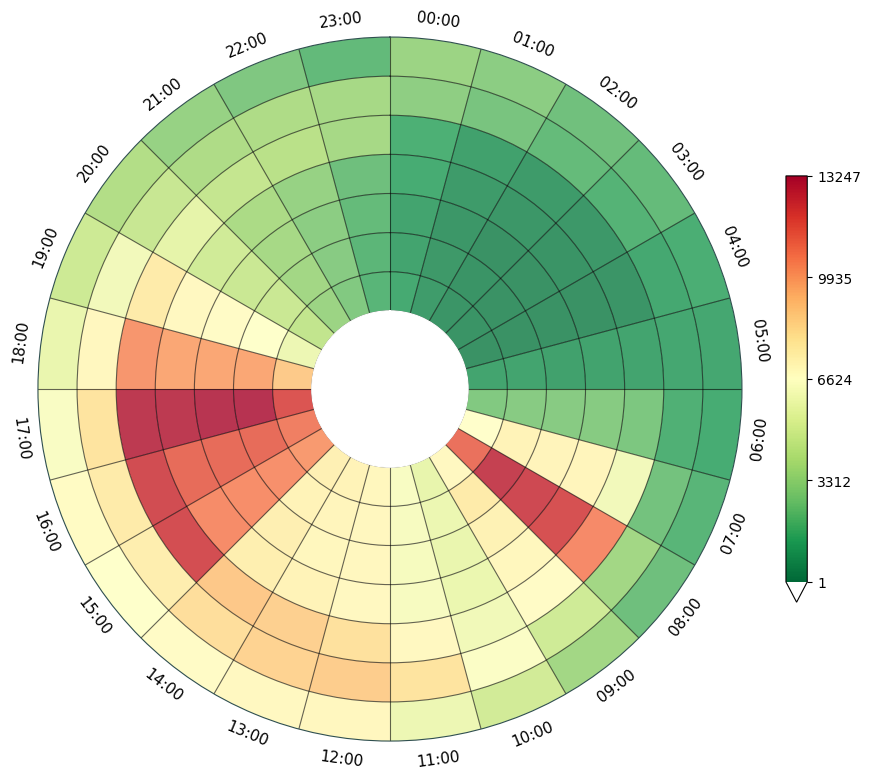
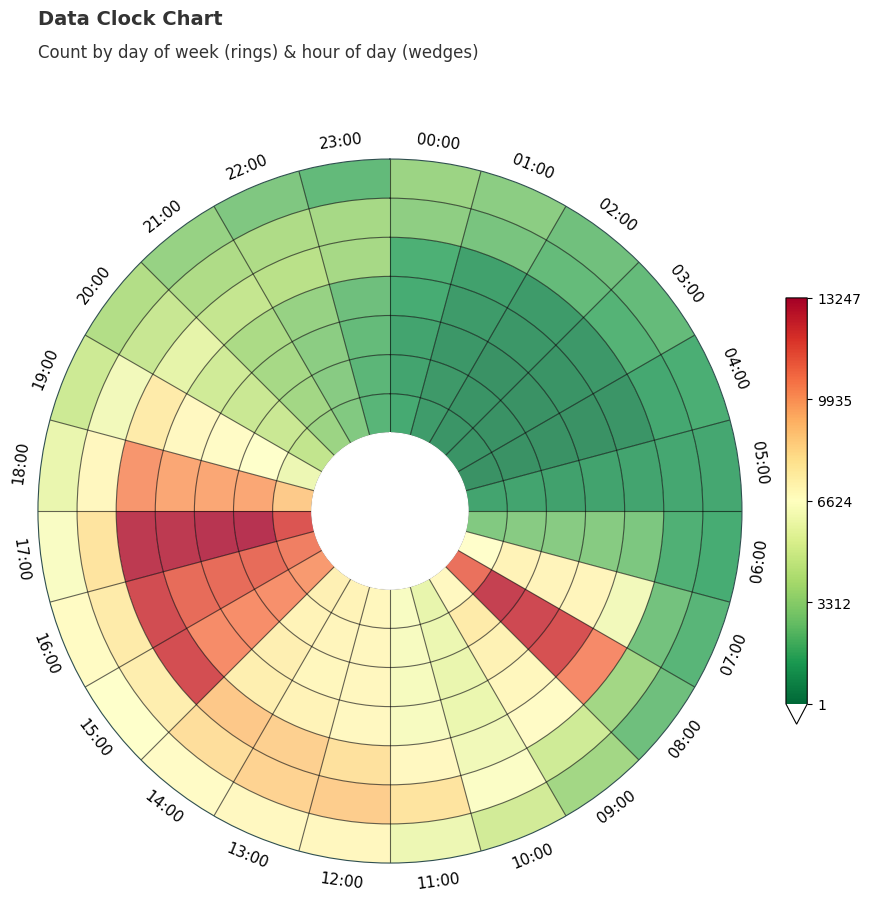
We can allow the function to generate some default text for the title and subtitle text areas.
chart_data, fig, ax = dataclock(
data=data,
date_column="Date_Time",
mode="DOW_HOUR",
spine_color="darkslategrey",
grid_color="black",
default_text=True
)
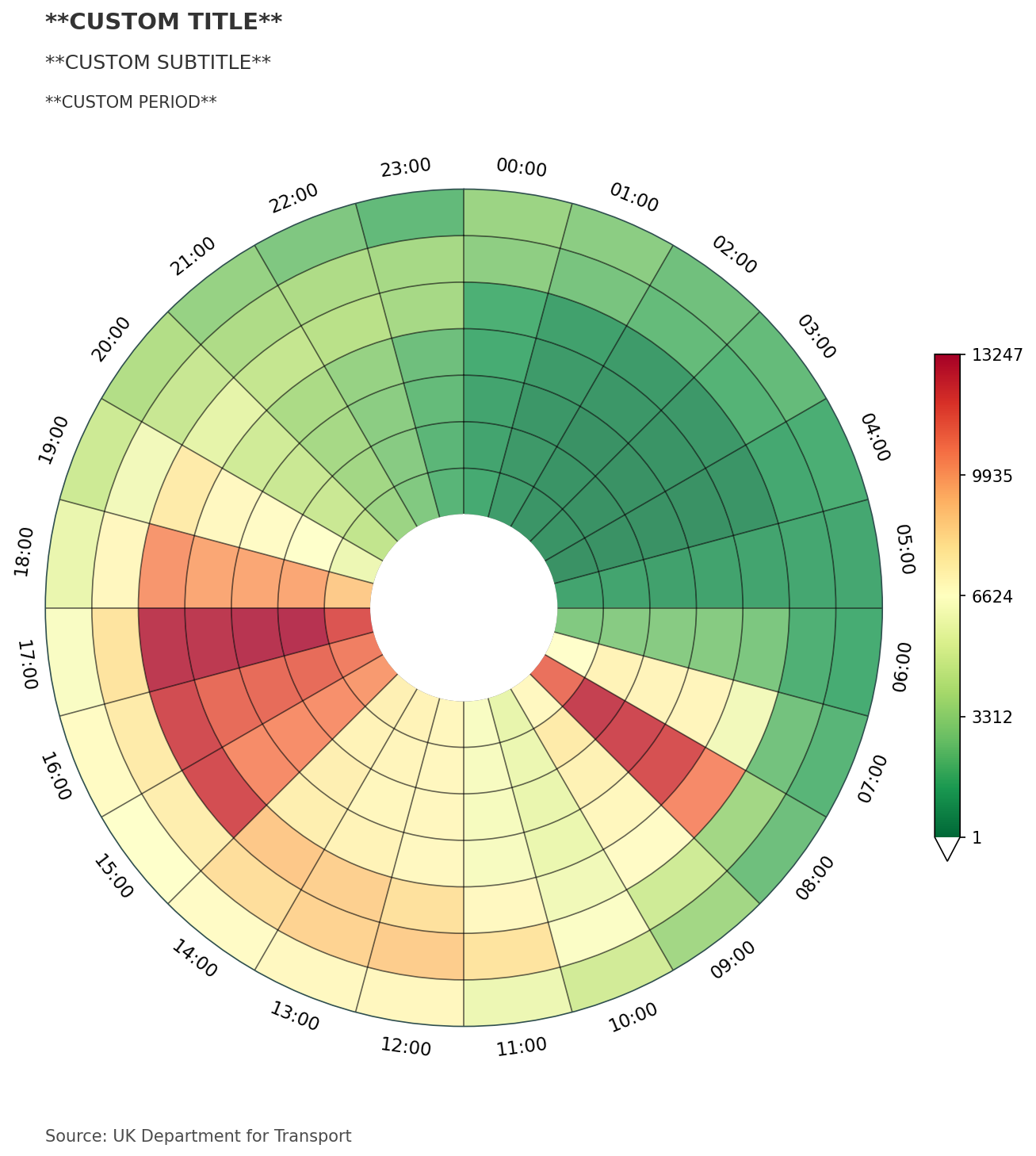
Next we will add our own title, subtitle and a third text element, which can be used to state the reporting period of the data. You could also use this space to add any other detail. We also make use of the chart_source parameter, which can be used to annotate the data source at the bottom of the chart. All of these text elements are dynamically spaced as the chart figure size grows and the number of rings change.
chart_data, fig, ax = dataclock(
data=data,
date_column="Date_Time",
mode="DOW_HOUR",
default_text=True,
spine_color="darkslategrey",
grid_color="black",
chart_title="**CUSTOM TITLE**",
chart_subtitle="**CUSTOM SUBTITLE**",
chart_period="**CUSTOM PERIOD**",
chart_source="Source: UK Department for Transport",
dpi=150
)
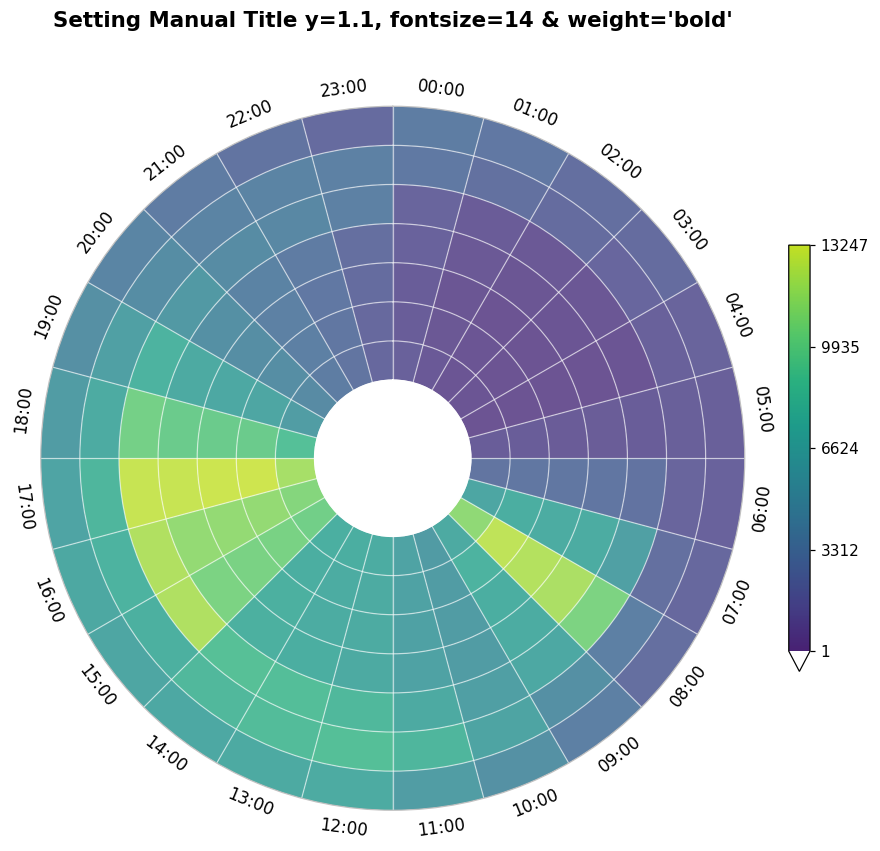
In the code below, all default titles have been removed (default_text=False) and with the Axes (ax) object, we manually set a chart title, adding an extra .1 to the y positioning, placing the title above the chart polar axis labels.
We also have access to the Figure object (fig), allowing for adjustment of the figure size. The figure size is automatically calculated by the dataclocklib.utility.get_figure_dimensions function based on the total number of individual wedges in each chart (minimum capped at [10,10]).
NOTE: Data clock charts work best with a square figure size, which must scale with the number of rings in the data when using different modes.
We have also adjusted the cmap_name parameter value used to display the graduated colors. This parameter refers to matplotlib colormap names.
from dataclocklib.utility import get_figure_dimensions
# 'DOW_HOUR' mode creates 24 wedges for each of the 7 rings (Monday - Sunday) - 168 wedges
get_figure_dimensions(chart_data["wedge"].size)
(11.0, 11.0)
chart_data, fig, ax = dataclock(
data=data,
date_column="Date_Time",
mode="DOW_HOUR",
cmap_name="viridis",
spine_color="silver",
grid_color="white",
default_text=False,
dpi=110
)
# set a custom title outside of dataclocklib API
ax.set_title(
"Setting Manual Title y=1.1, fontsize=14 & weight='bold'",
fontdict={"fontsize": 14, "weight": "bold"},
y=1.1
)
# set the figure size to (10,10)
fig.set_size_inches((10,10))
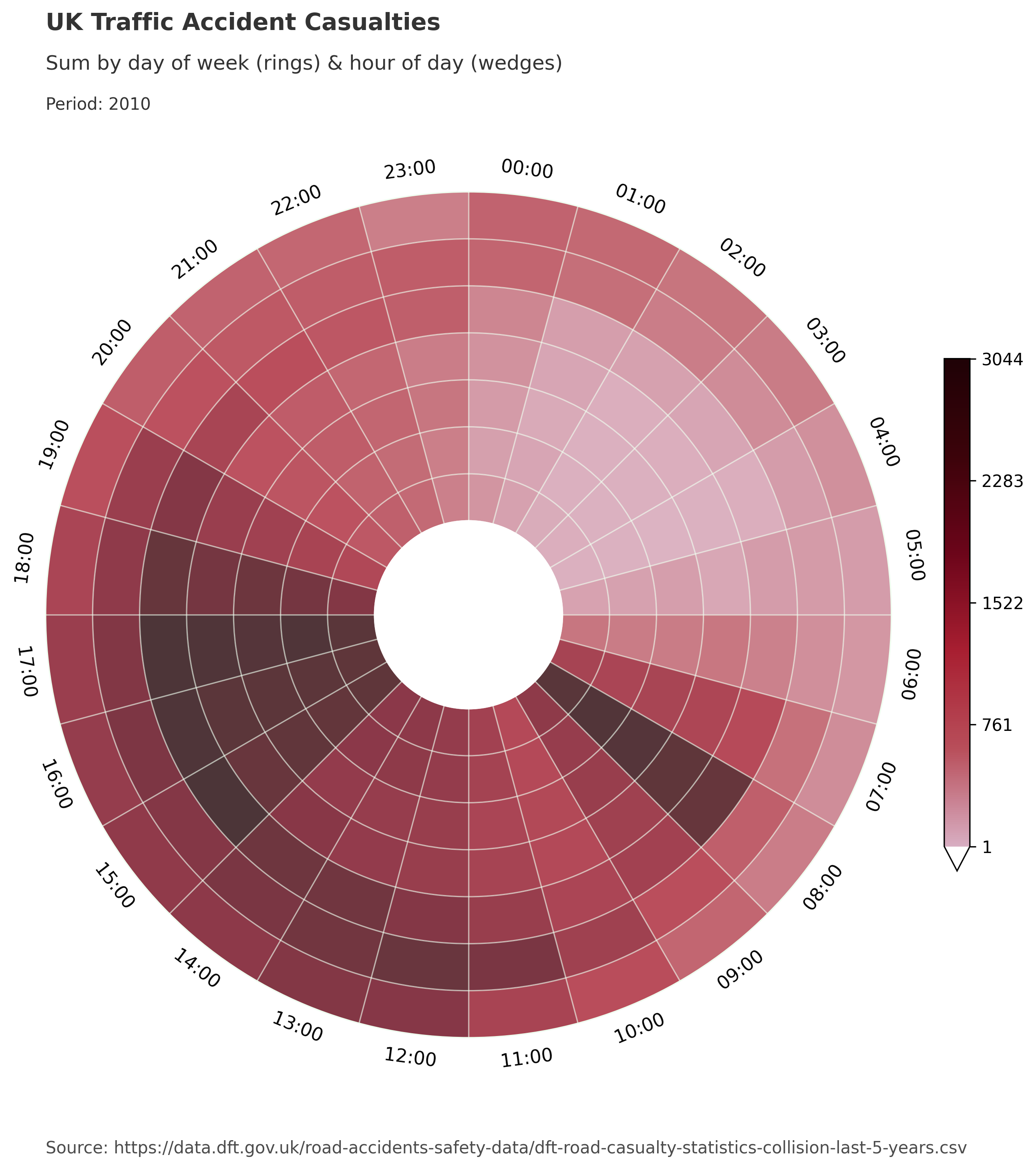
Below we generate a large chart with ‘WEEK_DAY’ mode, dividing traffic accident data for a full year into 52 rings for weeks of the year and 7 wedges for days of the week. As we chose an aggregation function ‘sum’, we also needed to specify a numeric column for aggregation. Here we chose a column representing the number of casualties in each accident (agg_column="Number_of_Casualties").
# BluYl X26 X3 X54 X58 a_palette pal12 RdYlGn_r
chart_data, fig, ax = dataclock(
data=data.query("Date_Time.dt.year.eq(2010)"),
date_column="Date_Time",
agg_column="Number_of_Casualties",
agg="sum",
mode="WEEK_DAY",
cmap_name="a_palette",
cmap_reverse=False,
default_text=True,
chart_title="UK Traffic Accident Casualties",
chart_subtitle=None,
chart_period="Period: 2010",
chart_source="Source: https://data.dft.gov.uk/road-accidents-safety-data/dft-road-casualty-statistics-collision-last-5-years.csv",
)
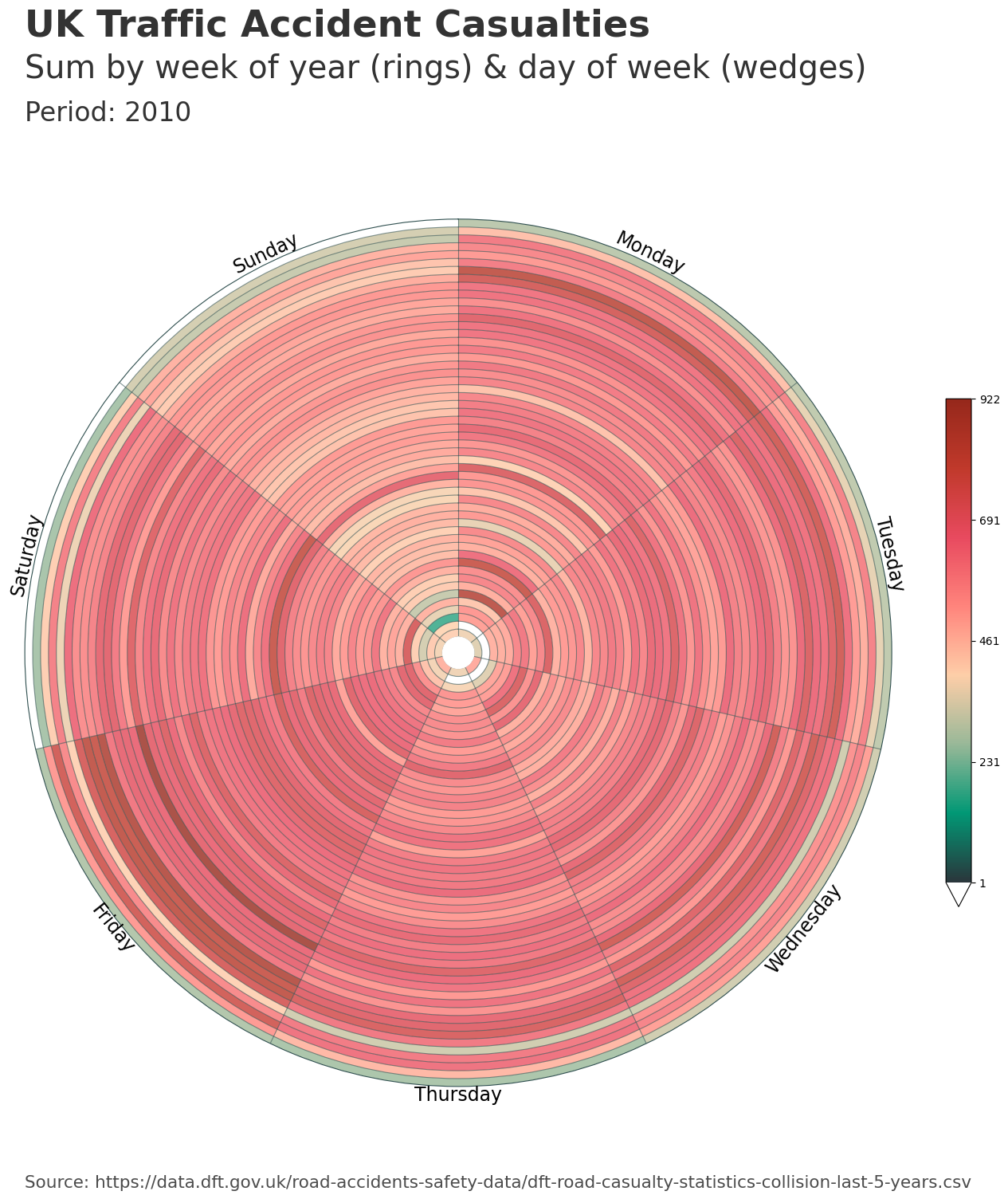
The dataclock function scales the text size and spacing in reference to the figure size, when using the chart_title, chart_subtitle, chart_period and chart_source parameters. The custom polar axis labels are dynamically spaced and scaled based on the number of rings.
We can check the figure dimensions and interface with any matplotlib API properties through the returned Axes & Figure objects.
fig.get_size_inches()
array([17., 17.])
This corresponds with the automatically calculated figure size within the dataclock function.
get_figure_dimensions(chart_data["wedge"].size)
(17.0, 17.0)
We can view the data that was aggregated and generated from our input data DataFrame, by looking at the first returned value. In these examples, this data is reference by the chart_data variable.
chart_data["ring"].nunique()
53
For the ‘WEEK_DAY’ mode and the relevant aggregations, the library uses the ISO date system. For this mode, the possible extra week (53) is not modified, in order to maintain the timing of events.
In the ISO week date system, weeks are numbered from 1 to 52 (or sometimes 53), with each week starting on Monday. A year can have 53 weeks when:
The year starts on a Thursday
The year starts on a Wednesday in a leap year
2010 saw its last week stretch into 2011, creating a ‘week 53’. January 1 2010, fell on a Friday - causing the last few days of December 2010 to end up in week 53.
When viewing the chart_data, we can see the different representations of the rings and wedges. For the ‘WEEK_DAY’ mode, the rings are created from the date_column year and week number and the wedges are formed from the days of the week.
chart_data
| ring | wedge | sum | |
|---|---|---|---|
| 0 | 201002 | 0 | 375 |
| 1 | 201002 | 1 | 349 |
| 2 | 201002 | 2 | 492 |
| 3 | 201002 | 3 | 372 |
| 4 | 201002 | 4 | 475 |
| ... | ... | ... | ... |
| 366 | 201052 | 2 | 323 |
| 367 | 201052 | 3 | 264 |
| 368 | 201052 | 4 | 275 |
| 369 | 201052 | 5 | 0 |
| 370 | 201052 | 6 | 0 |
371 rows × 3 columns
The ring and wedge column creation is handled by the dataclocklib.utility.assign_temporal_columns function.
from dataclocklib.utility import assign_temporal_columns
help(assign_temporal_columns)
Help on function assign_temporal_columns in module dataclocklib.utility:
assign_temporal_columns(data: pandas.core.frame.DataFrame, date_column: str, mode: Literal['YEAR_MONTH', 'YEAR_WEEK', 'WEEK_DAY', 'DOW_HOUR', 'DAY_HOUR']) -> pandas.core.frame.DataFrame
Assign ring & wedge columns to a DataFrame based on mode.
The mode value is mapped to a predetermined division of a larger unit of
time into rings, which are then subdivided by a smaller unit of time into
wedges, creating a set of temporal bins. These bins are assigned as 'ring'
and 'wedge' columns.
Args:
data (DataFrame): DataFrame containing data to visualise.
date_column (str): Name of DataFrame datetime64 column.
mode (Mode, optional): A mode key representing the
temporal bins used in the chart; 'YEAR_MONTH',
'YEAR_WEEK', 'WEEK_DAY', 'DOW_HOUR' & 'DAY_HOUR'.
Returns:
A DataFrame with 'ring' & 'wedge' columns assigned.
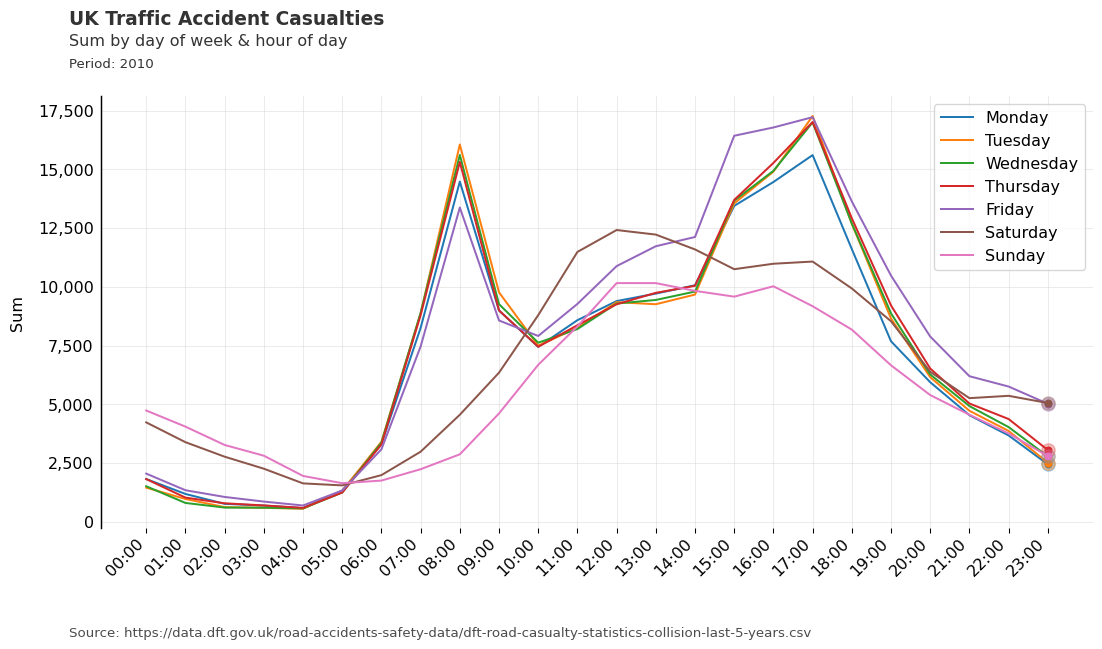
These rings and wedges could also be used to group and visualise the data in other formats, such as a line chart. In ‘DOW_HOUR’ mode, each unique ring could be plotted as a line, with the aggregation represented on the y-axis and the hours of the day on the x-axis.
The line chart is a work in progress and is included in dataclocklib as they can be used to identify temporal patterns that might be better visualised by a data clock chart. As mentioned above, they also lend themselves to easily utilising the library’s method of creating temporal bins.
from dataclocklib.charts import line_chart
chart_data, fig, ax = line_chart(
data=data.query("Date_Time.dt.year.ge(2010)"),
date_column="Date_Time",
agg_column="Number_of_Casualties",
agg="sum",
mode="DOW_HOUR",
default_text=True,
chart_title="UK Traffic Accident Casualties",
chart_subtitle=None,
chart_period="Period: 2010",
chart_source="Source: https://data.dft.gov.uk/road-accidents-safety-data/dft-road-casualty-statistics-collision-last-5-years.csv",
)
# BluYl X26 X3 X54 X58 a_palette pal12
chart_data, fig, ax = dataclock(
data=data.query("Date_Time.dt.year.eq(2010)"),
date_column="Date_Time",
agg_column="Number_of_Casualties",
agg="sum",
mode="DOW_HOUR",
cmap_name="X26", # Tam
cmap_reverse=True,
spine_color="honeydew",
grid_color="honeydew",
default_text=True,
chart_title="UK Traffic Accident Casualties",
chart_subtitle=None,
chart_period="Period: 2010",
chart_source="Source: https://data.dft.gov.uk/road-accidents-safety-data/dft-road-casualty-statistics-collision-last-5-years.csv",
dpi=300
)